
机器之心编辑部
嘿!刚刚,DeepSeek又更新了!
这次是更新了十月份推出的DeepSeek-OCR模型。
当时DeepSeek-OCR的出世,引起了大家对视觉压缩的关注与讨论,而这一次,DeepSeek对视觉编码下手了。
可以说,刚刚发布的DeepSeek-OCR2通过引入DeepEncoderV2架构,实现了视觉编码从「固定扫描」向「语义推理」的范式转变!
当然,和DeepSeek几乎每次发布一样,这一次同样也是模型和技术报告齐开源。
项目地址:https://github.com/deepseek-ai/DeepSeek-OCR-2
模型地址:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
这项研究的三位作者分别是魏浩然、孙耀峰、李宇琨。
具体来说,该研究的核心创新在于将原本基于CLIP的编码器替换为轻量级语言模型(Qwen2-500M),并引入了具有因果注意力机制的「因果流查询」。
这种设计打破了传统模型必须按从左到右、从上到下的栅格顺序处理图像的限制,赋予了编码器根据图像语义动态重排视觉Token的能力。通过这种两级级联的1D因果推理结构(编码器重排与译码器解析),模型能够更精准地还原复杂文档(如带表格、公式和多栏布局)的自然阅读逻辑。
这就像是为机器装上了「人类的阅读逻辑」,让AI不再只是生搬硬套地扫描图像。对比之下,传统的AI就像一个死板的复印机,不管页面内容多复杂,都只能从左上角到右下角按行扫描。
在维持极高数据压缩效率的同时,DeepSeek-OCR2在多项基准测试和生产指标上均取得了显著突破。模型仅需256到1120个视觉Token即可覆盖复杂的文档页面,这在同类模型中处于极低水平,显著降低了下游LLM的计算开销。
在OmniDocBenchv1.5评测中,其综合得分达到91.09%,较前代提升了3.73%,特别是在阅读顺序识别方面表现出了更强的逻辑性。
此外,在实际生产环境中,该模型显著降低了OCR识别结果的重复率,并为未来构建统一的omni-modal(全模态)编码器提供了可行路径。是的,未来同一个AI「大脑」或许能用同样的方法去处理声音、视频等所有模态的数据,真正实现多模态的深度统一。
DeepSeek-OCR2架构
如图3所示,DeepSeek-OCR2延续了DeepSeek-OCR的整体架构,由编码器(encoder)和解码器(decoder)组成。编码器负责将图像离散化为视觉token,而解码器则在这些视觉token与文本提示(textprompts)的条件约束下生成输出。
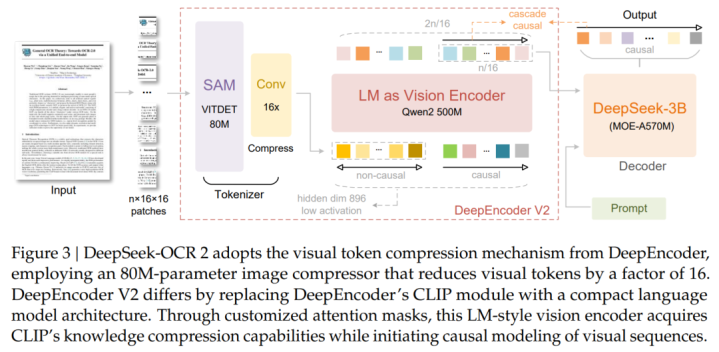
两者的关键区别在于编码器部分:DeepSeek将原有的DeepEncoder升级为DeepEncoderV2。在完整保留前代能力的基础上,DeepEncoderV2通过一种全新的架构设计,引入了因果推理能力(causalreasoning)。
DeepEncoderV2
DeepEncoderV2的第一个组成部分是视觉分词器(visiontokenizer)。延续了DeepEncoder的设计,DeepSeek采用了一种由参数规模为8000万的SAM-base与两层卷积层组成的架构。相比DeepEncoder,DeepSeek将最终卷积层的输出维度从1024降至896,以与后续处理流程保持一致。
在DeepEncoder中,视觉分词器之后接入的是一个CLIPViT,用于进一步压缩和建模视觉语义。DeepEncoderV2对这一组件进行了重新设计,将其改造为一种类LLM的架构,并引入了双流注意力机制(dual-streamattention)。
其中,视觉token采用双向注意力,以保留CLIP所具备的全局建模能力;而新引入的因果流查询(causalflowqueries)则使用因果注意力。这些可学习的查询token被作为后缀追加在视觉token之后,每个查询都可以关注所有视觉token以及其之前的查询token。通过保持查询token与视觉token数量一致,该设计在不改变token总数的前提下,对视觉特征施加语义上的排序与蒸馏约束。最终,只有因果查询token的输出会被送入LLM解码器。
从整体上看,该架构实际上构建了一种两阶段级联的因果推理机制:首先,编码器通过可学习查询对视觉token进行语义重排;随后,LLM解码器在这一有序序列之上执行自回归推理。与依赖位置编码施加刚性空间顺序的传统编码器不同,这种因果排序查询能够更自然地贴合连续的视觉语义,并与LLM的单向注意力模式高度一致。该设计有望在二维空间结构与一维因果语言建模之间搭建起一座桥梁。

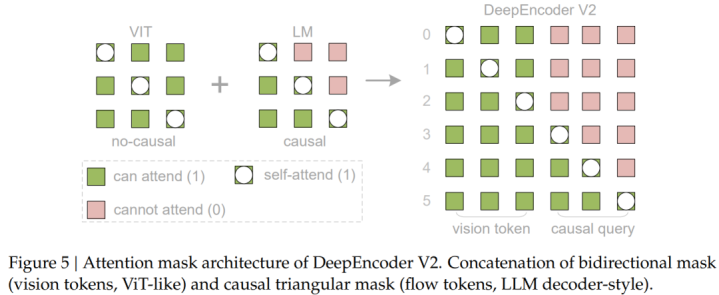
为更直观地展示DeepEncoderV2的注意力机制,图5对其注意力掩码进行了可视化。该注意力掩码由两个相互区分的区域组成。
左侧区域对原始视觉token采用双向注意力机制(类似于ViT),使任意token都可以与其他所有token建立可见性,从而实现完整的全局建模;右侧区域则针对因果流token使用因果注意力(三角形掩码,与纯解码器LLM完全一致),其中每个token只能关注其之前的token。
DeepSeek-MoEDecoder
由于DeepSeek-OCR2的改进重点主要集中在编码器上,并未对解码器部分进行升级。遵循这一设计原则,模型继续沿用DeepSeek-OCR的解码器——一个参数规模为30亿的MoE结构,其中约5亿参数在推理时处于激活状态。
训练数据与训练流程
在数据层面,DeepSeek-OCR2沿用了与DeepSeek-OCR相同的数据源,由OCR1.0、OCR2.0以及通用视觉数据组成,其中OCR数据占混合训练数据的80%。同时引入了以下两项改进:
针对OCR1.0数据采用了更均衡的采样策略,并按内容类型(正文、公式和表格)以3:1:1的比例对页面进行划分;
通过合并语义相似的类别(例如统一「插图说明」和「插图标题」)来优化布局检测的标签。
在训练阶段,DeepSeek-OCR2主要分为三个阶段来完成:(1)编码器预训练;(2)查询增强;(3)解码器专门化。
其中第一阶段使视觉分词器(tokenizer)和LLM风格的编码器获得特征提取、token压缩和token重排的基础能力。第二阶段进一步加强编码器的token重排能力,同时增强了视觉知识的压缩。第三阶段冻结编码器参数,仅优化解码器,从而在相同的FLOPs下实现更高的数据吞吐量。
接着来看细节。
首先是训练DeepEncoderV2。遵循DeepSeek-OCR和Vary的方法,使用语言建模目标来训练DeepEncoderV2,将编码器与轻量级解码器耦合,通过预测下一个token进行联合优化。采用了768×768和1024×1024两种分辨率的数据加载器。视觉分词器初始化自DeepEncoder,LLM风格的编码器则初始化自Qwen2-0.5B-base。预训练完成后,仅保留编码器参数用于后续阶段。
本阶段使用AdamW优化器,学习率采用余弦退火,从1e-4降至1e-6,在160台A100GPU(20个节点×8台GPU)上以640的批大小训练40k次迭代(采用长度为8K的序列打包,约包含1亿个图文对样本)。
其次是查询增强。在DeepEncoderV2预训练之后,将其与DeepSeek-3B-A500M整合为最终的流水线。冻结视觉分词器(SAM-conv结构),并联合优化LLM编码器和LLM解码器以增强查询表示。本阶段通过多裁剪策略将两种分辨率统一到单个数据加载器中。此外采用4阶段流水线并行:视觉分词器(PP0)、LLM风格编码器(PP1)以及DeepSeek-LLM层(PP2-3每阶段6层)。
本阶段利用160台GPU(每台40GB显存),配置了40个数据并行副本(每个副本4台GPU),过程中使用相同的优化器,以1280的全局批大小进行训练,学习率在15k次迭代中从5e-5退火至1e-6。
最后是LLM持续训练。为了快速消耗训练数据,本阶段冻结DeepEncoderV2的所有参数,仅更新DeepSeek-LLM的参数。本阶段加速了训练(在相同全局批大小下,训练速度提升了一倍多),同时有助于LLM更好地理解DeepEncoderV2重排后的视觉token。
承接第二阶段,本阶段进行了另一次学习率退火,从1e-6降至5e-8,共训练20k次迭代。
评估结果
团队选用OmniDocBenchv1.5作为主要评测基准,该基准包含1355页文档,覆盖中英文两种语言的9大主要类别,包括杂志、学术论文、研究报告等。凭借其多样化的测试样本与严格的评测标准,OmniDocBench为验证DeepSeek-OCR2的整体性能,尤其是DeepEncoderV2的有效性,提供了一个可靠有效的平台。
如表1所示,在使用最小视觉token上限(
)的情况下,DeepSeek-OCR2仍取得了91.09%的领先性能。与DeepSeek-OCR基线模型相比,在采用相似训练数据来源的前提下,其性能提升了3.73%,验证了新设计架构的有效性。
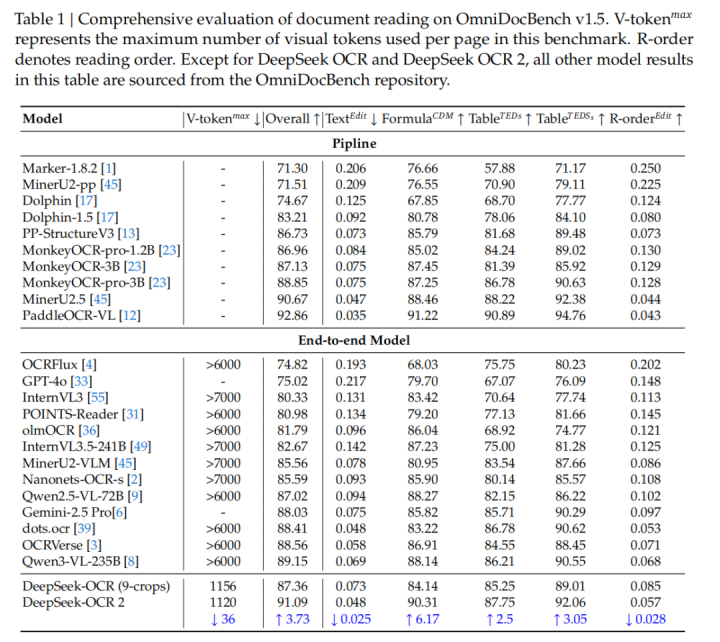
此外,除了整体性能提升,阅读顺序(R-order)指标上的编辑距离(EditDistance,ED)也显著下降,从0.085降至0.057。这表明,新的DeepEncoderV2能够根据图像信息更有效地选择并排列初始视觉token。
进一步如表2所示,在相同的视觉token预算(1120)条件下,DeepSeek-OCR2在文档解析任务中的ED(0.100)低于Gemini-3Pro(0.115)。这进一步证明了新模型在保持高视觉token压缩率的同时,仍能确保更优的性能,并展现出极高的潜力。
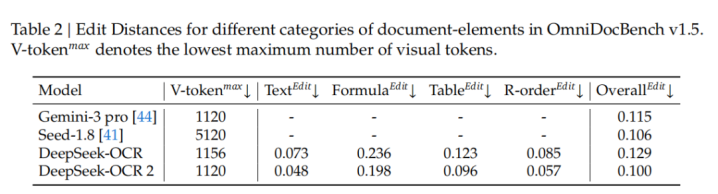
改进空间
团队在9种文档类型上,对DeepSeek-OCR与DeepSeek-OCR2进行了细致的性能对比,结果表明:DeepSeek-OCR2仍具有较大的提升空间,如表3所示。在文本识别的编辑距离(ED)指标上,DeepSeek-OCR2在大多数场景中优于DeepSeek-OCR,但在某些类型上仍存在明显不足,例如报纸类文档,其ED超过0.13。
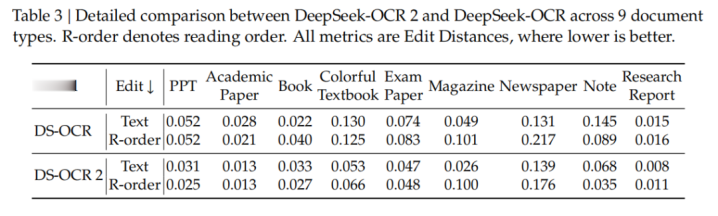
团队认为主要原因有两点:
视觉token上限较低,可能影响了文本极为密集的报纸类文档识别效果,这一问题可在未来通过增加局部裁剪(localcrops)的数量来缓解;
报纸类数据不足——当前训练集中仅包含约25万条相关样本,这对于训练DeepEncoderV2来说仍然不够充分。
当然,在阅读顺序(R-order)这一指标上,DeepSeek-OCR2在所有类别中始终优于DeepSeek-OCR,这进一步验证了所提出的「视觉因果流」编码器设计的有效性。
实际应用
DeepSeek-OCR主要面向两类生产场景:一是为DeepSeek-LLM提供图像/文档读取能力的在线OCR服务,二是用于批量PDF处理的预训练数据流水线。在比较了DeepSeek-OCR2与DeepSeek-OCR在真实生产环境中的表现后发现,由于生产环境中无法获得标准答案,因此团队主要采用「重复率」作为核心质量指标。
如表4所示,相比前代模型,DeepSeek-OCR2在实际可用性方面有了显著提升:在在线用户日志图像中,重复率从6.25%降至4.17%;在PDF数据生产场景中,重复率从3.69%降至2.88%。

这些结果进一步验证了DeepSeek-OCR2架构的有效性,尤其体现了其在逻辑性视觉理解方面的优势。
配资炒股利息,股票配资网址是什么,配资官网开户提示:文章来自网络,不代表本站观点。







